
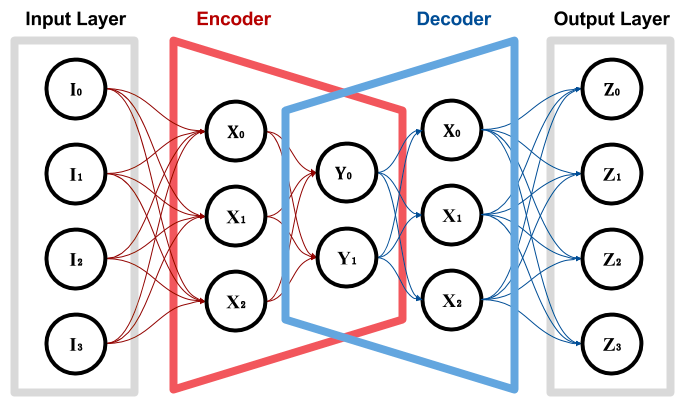
今天我們來討論一個進化的AutoEncoder - Variational AutoEncoder。先回顧一下AutoEncoder的架構,AutoEncoder的架構圖如下,
AutoEncoder的目標就是希望利用深度學習網絡,透過降維 (Encoder) 以及升維 (Decoder),來 train整個Model 。其最終目標是希望能找到關鍵維度並使Input layer跟Output layer越接近越好。而單純的AurtoEnooder還是有一些performance的限制,可能在將維度還原的時候還是沒辦法做得很好。因此,就有了Variational AutoEncoder。
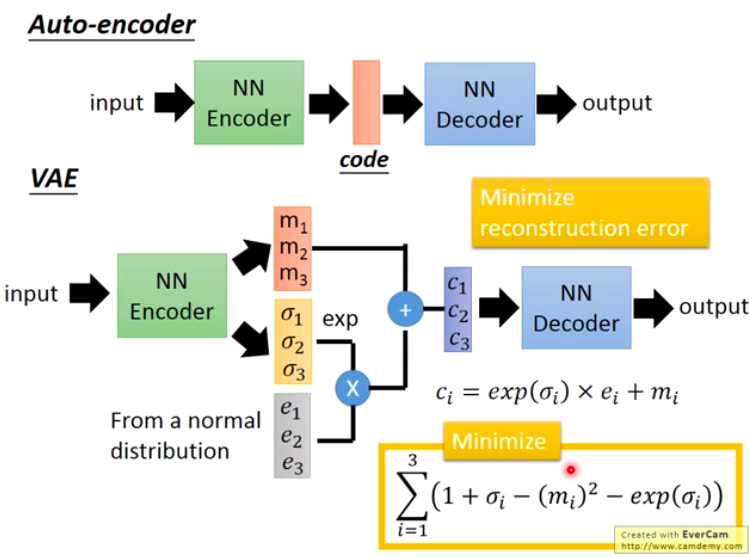
VAE的架構如下:
簡單來說VAE加入了一些noise進去AutoEncoder Learn,透過Normal distribution的抽樣讓結果更好。除此之外,在衡量模型的部分,他使用了 KL divergence (簡單說,用以衡量分配相似度,可以參考以下內容,數學內容重度!)
接下來我們就開始實做吧,今天也是一樣使用Fashion MNITS。和昨天的AutoEncoder是一樣的,也是相同的方法Load資料
(x,y),(x_test,y_test) = datasets.fashion_mnist.load_data()
data = tf.data.Dataset.from_tensor_slices(x)
data = data.map(feature_scale).shuffle(10000).batch(128)
data_test = tf.data.Dataset.from_tensor_slices(x_test)
data_test = data_test.map(feature_scale).batch(128)
接下來是VAE的模型重點,首先我們定義encoder各層的layer,而每一層都是Dense所組成的。接下來就是透過Encoder,output mean 跟 variance。針對Mean 跟 Variance 計算的結果,可以透過下面所定義的reparameter 進行計算。最後把所有一起合併起來寫一個forward的call function!
class VAE(keras.Model):
def __init__(self):
super(VAE,self).__init__()
#encoder
self.fc_layer_1 = layers.Dense(128)
self.fc_layer_2 = layers.Dense(dim_reduce)
self.fc_layer_3 = layers.Dense(dim_reduce)
self.fc_layer_4 = layers.Dense(128)
self.fc_layer_5 = layers.Dense(784)
def model_encoder(self, x):
h = tf.nn.relu(self.fc_layer_1(x))
mean_fc = self.fc_layer_2(h)
var_fc = self.fc_layer_3(h)
return mean_fc,var_fc
def model_decoder(self, z):
out = tf.nn.relu(self.fc_layer_4(z))
out = self.fc_layer_5(out)
return out
def reparameter(self,mean_x,var_x):
eps = tf.random.normal(var_x.shape)
std = tf.exp(var_x)**0.5
z = mean_x + std*eps
return z
def call(self, inputs, training=None):
mean_x,var_x = self.model_encoder(inputs)
z = self.reparameter(mean_x,var_x)
x = self.model_decoder(z)
return x,mean_x,var_x
接下來就是training的部分,這邊比較特別是KL divergence來自己寫。主要會透 tf.nn.sigmoid_cross_entropy_with_logits 以及 tf.reduce_sum / x.shape[0] 來計算error 跟 KL divergence 計算 loss 。最後在利用這個loss 來update 參數
for i in range(10):
for step,x in enumerate(data):
x = tf.reshape(x,[-1,784])
with tf.GradientTape() as tape:
logits,mean_x,var_x = model(x)
loss = tf.nn.sigmoid_cross_entropy_with_logits(labels=x,logits=logits)
loss = tf.reduce_sum(loss)/x.shape[0]
kl_div = -0.5*(var_x+1-mean_x**2-tf.exp(var_x))
kl_div = tf.reduce_sum(kl_div)/x.shape[0]
loss = loss + 1.*kl_div
grads = tape.gradient(loss,model.trainable_variables)
optimizer.apply_gradients(zip(grads,model.trainable_variables))
最後我們比較一下AE 跟 VAE 的結果吧

可以看出來同樣train 10圈下,VAE的結果較佳
這次AE的部份到這邊,明天後天應該會來討論GAN的部分。感謝大家漫長的閱讀~

{kind=link}